Saving a website #tlah
Sometimes when you are researching for a project, you’ll come across web resources that you would like to save. Now, you can bookmark it, or use a bookmarking service, but there is still a chance that when you go back to the site it may be gone (and archive.org) may not have a copy. To make sure that doesn’t happen, use the Save Page As… feature in your browser.
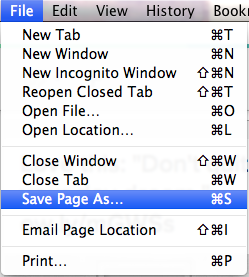
The above screenshot is from Google Chrome, but most browsers support this feature. What it does is creates a .html file in the location you choose, named after the title of the page. Along with the .html file, the browser will create a folder and put the assets of the webpage (mostly graphics and pictures) in that folder. When finished, you have a mostly complete copy of the web page. Why do I say mostly? Because if the page was highly interactive, or pulled resources from other sites, the browser may not have grabbed everything. From my experience, it does a pretty good job of it.
Another advantage to this method is the ability to use your computer’s built-in search to find resources. When you execute a search, it will also go through any web pages that you may have downloaded.
If you are on OS X (or have installed a PDF printer on your computer), you can also use the Print command to print the webpage as a PDF. This encases the entire page in one file. I can’t think of a good reason to use Save Page As… over Print, so use whatever works best for you!